- Created flowcharts for Infra adapters, artifacts, high-level process, models, and tests in the DOCS/diagrams directory. - Added a mkdocs.yml configuration file for documentation site setup.
18 KiB
Arquitectura técnica — Canalización Multimedia (Whisper + Kokoro)
Esta página es la versión unificada de la documentación de arquitectura para MkDocs. Describe la estructura por capas, el flujo orquestado por whisper_project/main.py y las recomendaciones prácticas.
Resumen rápido
Diagrama sencillo (texto)
[Video] --> [Extract audio (ffmpeg)] --> [Transcribe (whisper)]
--> [Translate (local/gemini)] --> [Generate SRT]
--> [Kokoro TTS per-segment] --> [Concat WAVs] --> [Replace/Mix audio]
--> [Burn subtitles] --> [output/<basename>/]
Diagrama Mermaid (alto nivel)
flowchart LR
VInput["Video input"] --> ExtractAudio["Extract audio\n(ffmpeg)"]
ExtractAudio --> Transcribe["Transcription\n(faster-whisper / openai-whisper)"]
Transcribe --> Segments["Segments\n(start/end/text)"]
Segments --> Translate["Translation decision\n(usecase)"]
Translate -->|local| LocalTranslate["Local MarianMT\n(Helsinki-NLP)"]
Translate -->|remote| GeminiAPI["Gemini / LLM HTTP API"]
LocalTranslate --> SRTGen["Generate SRT\n(translated) "]
GeminiAPI --> SRTGen
SRTGen --> KokoroTTS["Kokoro TTS\n(per-segment synth)"]
KokoroTTS --> ChunkAdjust["Align / Pad / Trim\n(per segment)"]
ChunkAdjust --> Concat["Concat / Normalize WAVs"]
Concat --> AudioProc["FFmpeg Audio Proc\n(replace or mix)"]
AudioProc --> BurnSubs["Burn subtitles (ffmpeg)"]
BurnSubs --> Output["output/<basename>/\n(final artifacts)"]
subgraph InfraAdapters [Infra adapters]
ExtractAudio
Transcribe
KokoroTTS
AudioProc
end
subgraph Usecase [Usecase / Orchestrator]
Transcribe
Translate
SRTGen
Concat
end
%% auxiliary services
Logs["Logging (logs/infra, logs/usecases, logs/cli)"]
Cache["Model cache (~/.cache/transformers)"]
Logs -.-> Transcribe
Logs -.-> KokoroTTS
Cache -.-> Transcribe
Cache -.-> LocalTranslate
classDef infra fill:#f8f9fa,stroke:#0366d6,color:#000
class InfraAdapters infra
Fuente del diagrama: DOCS/diagrams/adapters.mmd
Fuente del diagrama: DOCS/diagrams/artifacts.mmd
Fuente del diagrama: DOCS/diagrams/models.mmd
Fuente del diagrama: DOCS/diagrams/tests.mmd
Imagen del diagrama
Si prefieres una imagen estática, está incluida en DOCS/assets/pipeline_diagram.png y se referencia aquí de forma relativa:

Nota: este archivo vive en
DOCS/architecture.mdy usa la carpetaDOCS/assets/para los recursos embebidos.
Diagramas detallados
A continuación se incluyen las versiones estáticas (PNG) de los diagramas generados a partir de los ficheros Mermaid en DOCS/diagrams/. Estas imágenes se incluyen para que MkDocs pueda servirlas rápidamente sin depender del render en tiempo real.
Diagrama general (alto nivel)
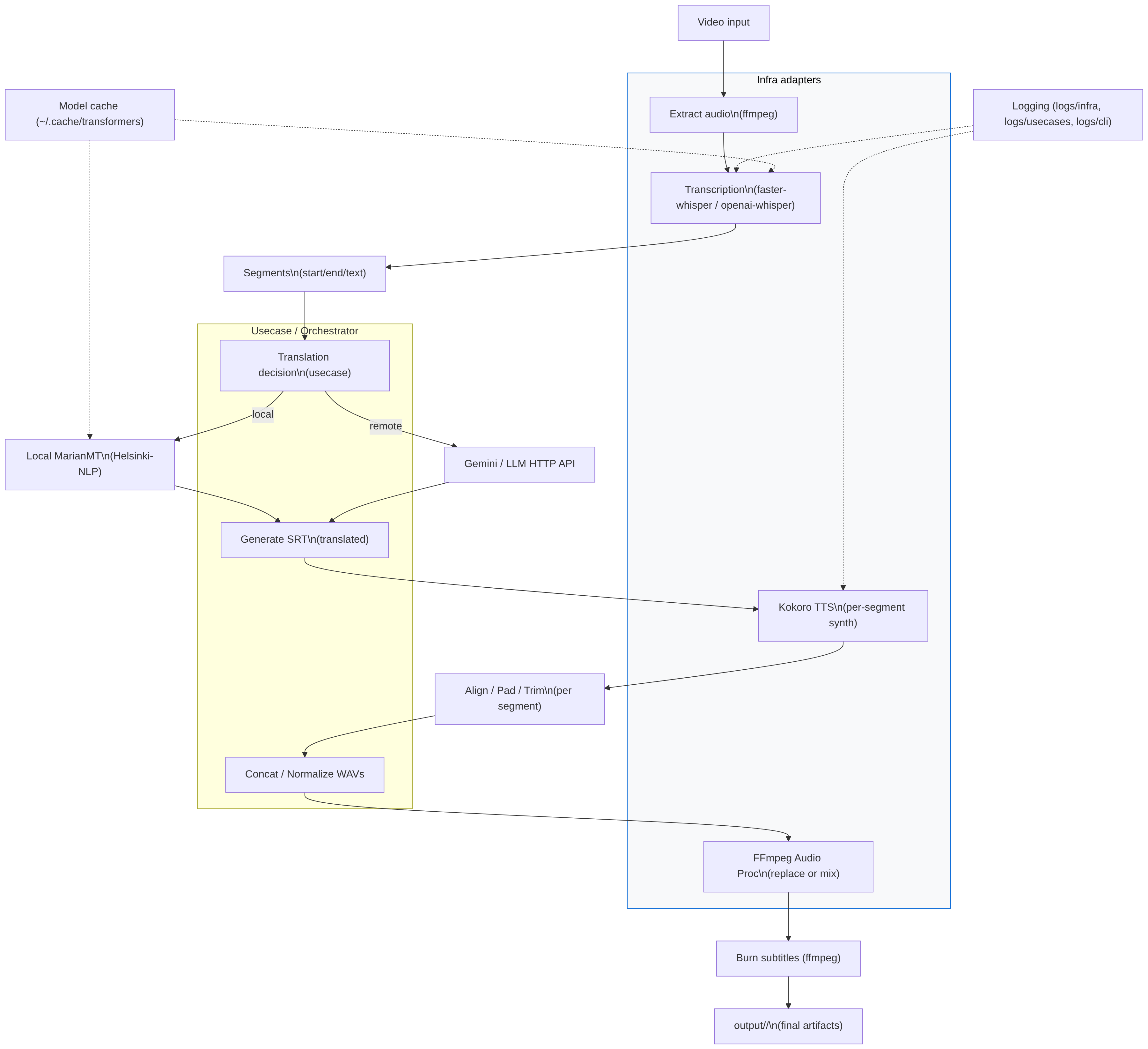
Fuente: DOCS/diagrams/high_level.mmd
Adaptadores (infra)

Fuente: DOCS/diagrams/adapters.mmd
Artefactos y logging
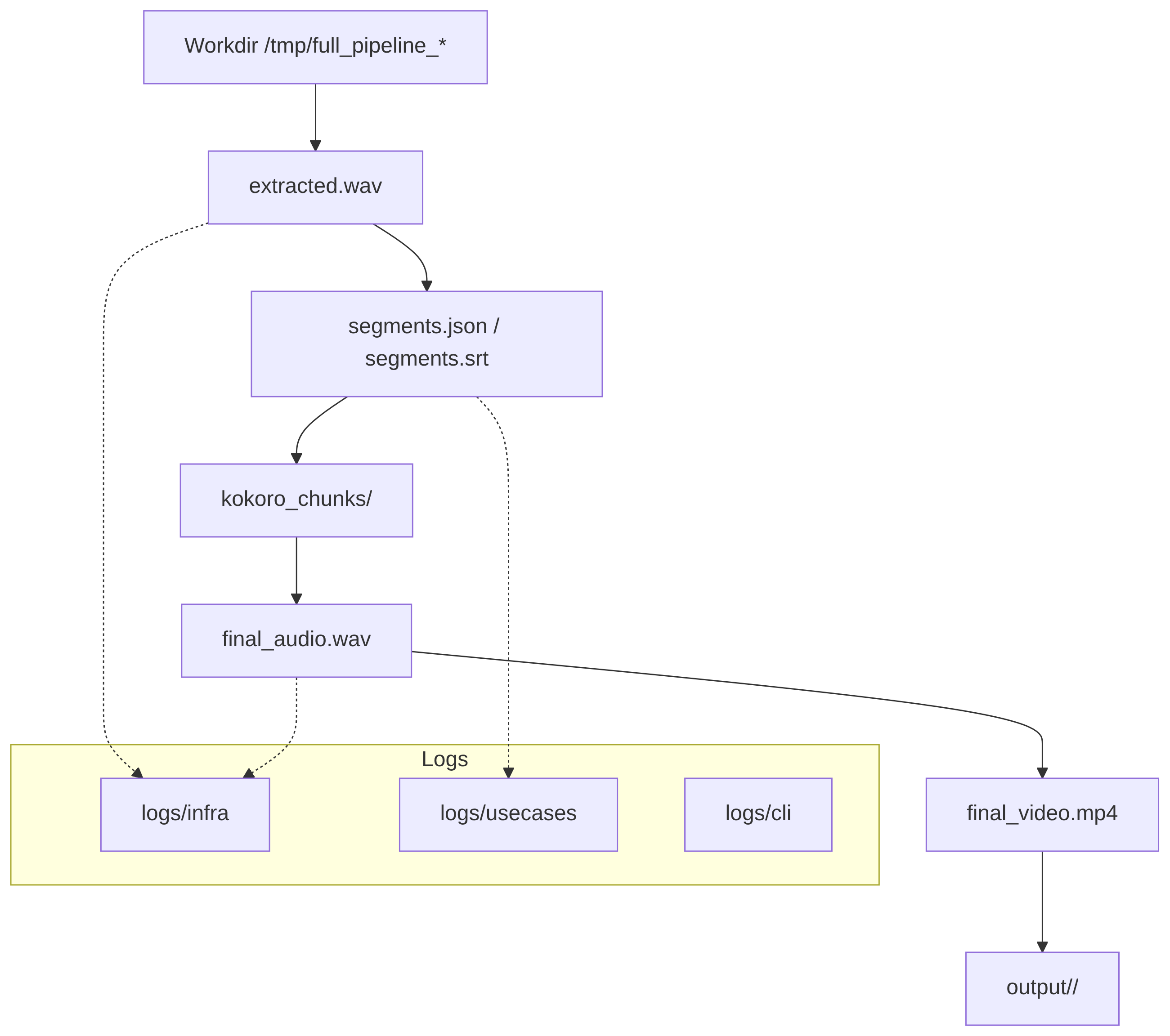
Fuente: DOCS/diagrams/artifacts.mmd
Modelos y caché
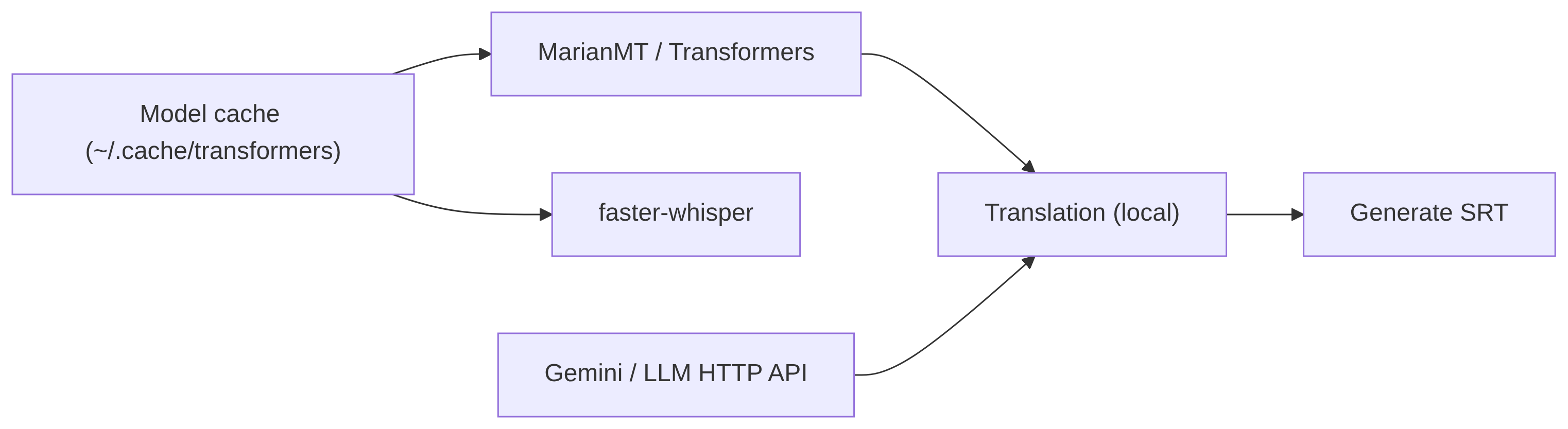
Fuente: DOCS/diagrams/models.mmd
Pruebas y despliegue
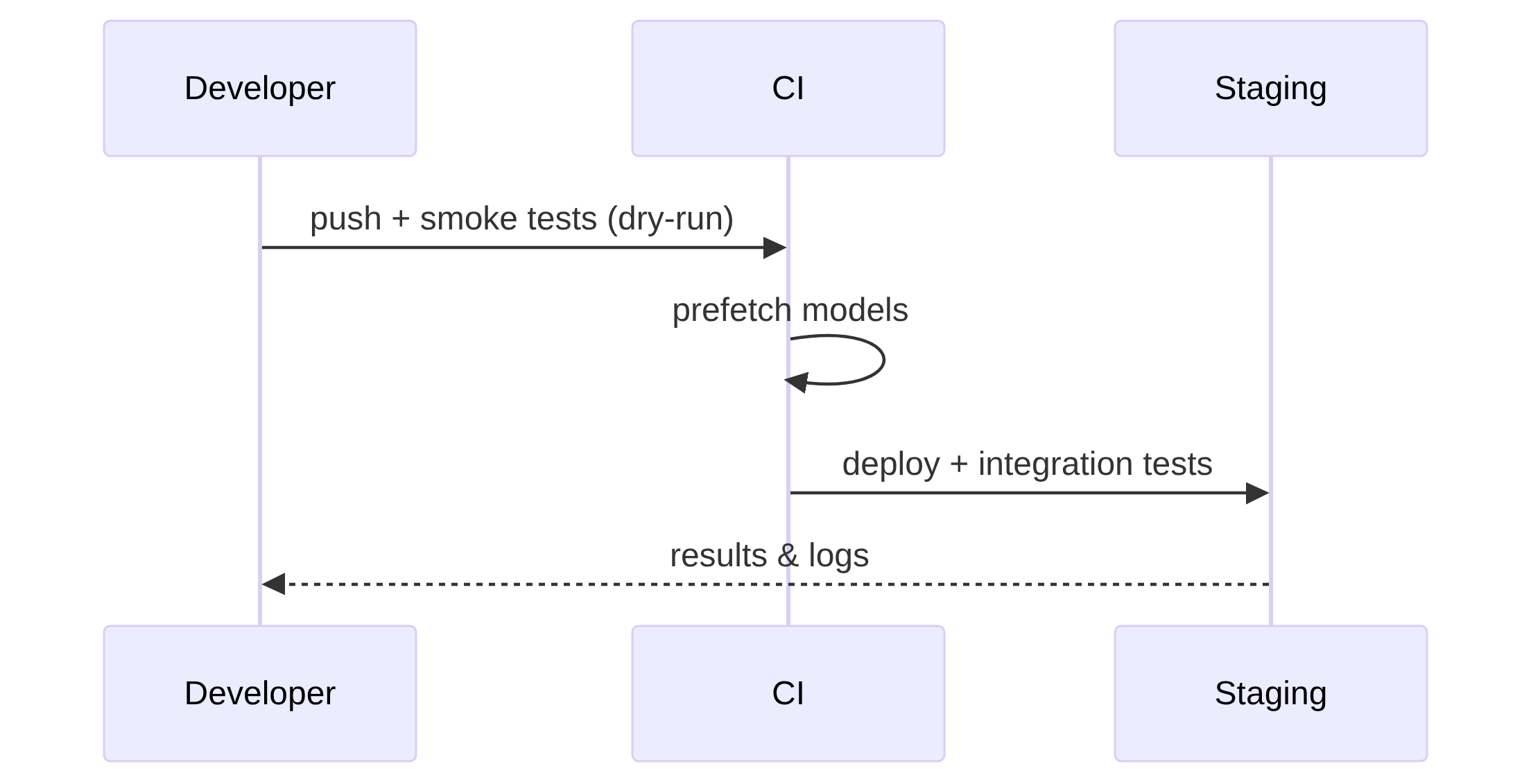
Fuente: DOCS/diagrams/tests.mmd
Flujo de trabajo (pipeline)
Los pasos principales orquestados por PipelineOrchestrator son:
- Crear directorio temporal de trabajo (workdir) en
/tmp/full_pipeline_<id>. - Extraer audio del vídeo (ffmpeg) -> WAV.
- Transcribir audio a segmentos (faster-whisper / openai-whisper).
- Traducir segmentos (opciones: local MarianMT, Gemini remoto, etc.).
- Generar SRT traducido.
- Sintetizar cada segmento con Kokoro TTS (por segmentos) y ajustar duración.
- Concat/normalizar chunks y producir WAV final.
- Reemplazar o mezclar la pista de audio del vídeo original.
- Quemar SRT en el vídeo y mover artefactos a
output/<basename>/. - Limpieza: borrar workdir y, por defecto, limpiar
/tmp/full_pipeline_*salvo--keep-temp.
Adaptadores y shims
Esta capa agrupa los componentes que actúan como "puentes" entre la lógica del orquestador y el mundo exterior (subprocess, HTTP, librerías de ML). Son responsables de encapsular detalles operativos y exponer contratos simples y estables al orquestador.
Objetivos y responsabilidades
- Encapsular llamadas a herramientas externas (ffmpeg), servicios HTTP (Kokoro, Gemini) y librerías locales (faster-whisper, transformers).
- Normalizar entradas/salidas: devolver estructuras de datos (por ejemplo, objetos Segment) en vez de rutas o strings sueltos.
- Manejar retries, timeouts y errores transitorios; transformar errores externos en excepciones del dominio que entiende el orquestador.
- Registrar eventos relevantes y métricas (latencias, tamaños de payload, códigos HTTP).
- Ser conservadores con efectos secundarios: no deben cambiar directorios globales ni variables de entorno; trabajan dentro del
workdirproporcionado.
Estructura recomendada (contratos)
- TranscribeAdapter
- entrada: path a WAV
- salida: lista de Segment {start, end, text, confidence}
- KokoroTTSAdapter
- entrada: texto del segmento, voz, modelo
- salida: path a WAV sintetizado
- FFmpegAdapter
- métodos: extract_audio(video)->wav, replace_audio(video,audio)->video_out, burn_subtitles(video,srt)->video_out
Buenas prácticas
- Inyectar adaptadores en el orquestador (dependency injection) para facilitar tests.
- Envolver todas las llamadas a 3rd-party en try/except y lanzar excepciones propias (ej. AdapterError, TemporaryAdapterError).
- Exponer parámetros configurables (timeouts, max_retries, backoff).
- Emitir logs estructurados (JSON opcional) si se quiere integrar con sistemas de observabilidad.
Mermaid: vista de Adaptadores
Logging, artefactos y flags importantes
Esta sección describe cómo se registran eventos, qué artefactos produce la canalización y los flags CLI esenciales.
Logging
- Carpetas recomendadas:
logs/infra/— logs de adaptadoreslogs/usecases/— logs del orquestador y reglas de negociologs/cli/— logs de la capa de entrada (parsing de flags)
- Configuración típica:
- Console handler: nivel INFO (DEBUG con
--verbose) - File handler: RotatingFileHandler (5 MB, 5 backups)
- Formato:
%(asctime)s %(levelname)s %(name)s: %(message)s
- Console handler: nivel INFO (DEBUG con
Artefactos producidos
workdir(temporal):/tmp/full_pipeline_<id>/extracted.wav— audio extraídosegments.json/segments.srt— segmentos y SRT generadokokoro_chunks/— WAVs por segmentofinal_audio.wav— WAV concatenado y normalizadofinal_video.mp4— vídeo con la pista de audio resultanteburned_video.mp4— vídeo con subtítulos quemados (opcional)output/<basename>/— carpeta final cuando no es--dry-run
Flags importantes (resumen)
--video PATH(required): archivo de entrada--srt PATH(optional): usar SRT existente--kokoro-endpoint/--kokoro-key--voice,--kokoro-model--translate-method[local|gemini|none]--gemini-key--dry-run,--keep-temp,--keep-chunks--mix,--mix-background-volume--verbose(DEBUG)--logs-dir(opcional): personalizar ubicación de logs
Mermaid: artefactos y logging
Gestión de modelos
Resumen
- Transcripción:
faster-whisper,openai-whisper(local) o servicios remotos. - Traducción local: MarianMT (
transformers). - Traducción remota / LLM: Gemini u otros endpoints HTTP.
Recomendaciones operativas
- Usar
TRANSFORMERS_CACHEo un cache compartido en CI para evitar descargas repetidas. - Preferir modelos
base/smallpara ejecuciones CPU;medium/largerequieren GPU/VRAM. - Para
faster-whisper, usarcompute_type=int8o q4 para reducir memoria cuando sea posible. - No almacenar credenciales en el repo; usar variables de entorno (
KOKORO_KEY,GEMINI_KEY) o secret manager.
Mermaid: flujo de modelos y cache
Recomendaciones y pruebas
Flujo recomendado para desarrollo y CI
--dry-runpara validar flags y rutas sin escribiroutput/.- Smoke test local: ejecutar pipeline contra un fixture corto (10s) con adaptadores fakes o endpoints de staging.
- Integración: ejecutar en staging con servicios reales y
--keep-tempactivado para debugging. - Producción: ejecutar con modelos y recursos adecuados (GPU si procede) y recolección de métricas.
Qué probar en CI
- Unit tests: adaptadores (mocks), orquestador (fakes), validación de argumentos.
- Smoke: pipeline en
--dry-runpara validar el flujo completo sin artefactos pesados. - Prefetch: job que descarga y cachea modelos antes de la ejecución principal.
Checklist de documentación adicional
- Incluir ejemplos de payloads HTTP para Kokoro (request/response) y plantillas
curl. - Añadir snippets de
ffmpegpara extracción, reemplazo y burn de subtítulos. - Documentar un ejemplo SRT de entrada y salida.
- Incluir guía de pre-cacheo de modelos y variables de entorno requeridas.
Mermaid: flujo de pruebas y despliegue
Si quieres, puedo aplicar este contenido directamente en DOCS/architecture.md (reemplazando las secciones vacías) — dime si lo hago ahora. También puedo extraer los bloques Mermaid a archivos separados DOCS/diagrams/*.mmd si prefieres tenerlos aislados.
Arquitectura técnica — Canalización Multimedia (Whisper + Kokoro)
Este documento describe, a nivel técnico, cómo está organizada la iniciativa del proyecto y cómo funciona el flujo orquestado por run_full_pipeline / whisper_project/main.py.
Contenido breve:
- Entrypoints y ejecución
- Capas arquitectónicas (Usecases / Infra / CLI)
- Flujo de trabajo (pasos del pipeline)
- Adaptadores y shims
- Logging, artefactos y limpieza
- Flags/claves importantes y recomendaciones
- Errores comunes y debugging rápido
- Entrypoints y ejecución
- Punto canónico:
whisper_project/main.py— contiene la funciónmain()que construye adaptadores por defecto e invoca el usecase orquestador (PipelineOrchestrator). - Compatibilidad histórica:
whisper_project/run_full_pipeline.pyes un "shim" que simplemente delega awhisper_project.main:mainpara preservar la interfaz previa. - Recomendación de ejecución desde la raíz del repo:
.venv/bin/python3 -m whisper_project.run_full_pipeline \ # o -m whisper_project.main
--video /ruta/al/video.mp4 --kokoro-endpoint "https://..." \
--kokoro-key "$KOKORO_TOKEN" --voice em_alex --whisper-model base
Ejecutar el archivo directamente (p. ej. python whisper_project/run_full_pipeline.py) puede requerir ajustar PYTHONPATH=., porque Python resuelve paquetes según sys.path. Usar -m evita ese problema.
- Capas arquitectónicas
El proyecto sigue una aproximación inspirada en Clean Architecture:
whisper_project/usecases/— lógica de orquestación y casos de uso (p. ej.PipelineOrchestrator). Aquí residen las reglas de negocio que coordinan los pasos del pipeline.whisper_project/infra/— adaptadores concretos hacia herramientas y servicios externos (ffmpeg, Kokoro TTS, backends de transcripción/Traducción). Ejemplos:ffmpeg_adapter.py— wrappers para extracción, reemplazo y burn de subtítulos.kokoro_adapter.py— cliente HTTP hacia el endpoint TTS (sintetiza por segmento y devuelve WAVs).transcribe_adapter.py— compatibilidad con backends como faster-whisper o openai-whisper.
whisper_project/cli/y scripts shim — pequeñas interfaces de línea de comandos que exponen utilidades concretas (por compatibilidad y tests).whisper_project/logging_config.py— configuración centralizada de logging, crea carpetaslogs/infra,logs/usecases,logs/cliy handlers rotativos.
- Flujo de trabajo (pipeline)
Pasos principales que orquesta PipelineOrchestrator:
- Crear directorio temporal de trabajo (workdir) en
/tmp/full_pipeline_<id>. - Extraer audio del vídeo (ffmpeg) -> WAV.
- Transcribir audio a segmentos (faster-whisper / openai-whisper) -> segmentos con start/end/text.
- Traducir segmentos (opciones):
- local: MarianMT/Marian-based adapters
- gemini: llamada remota HTTP a API tipo Gemini (con key)
- argos / otros: adapters alternativos
- Generar SRT traducido a partir de segmentos.
- Sintetizar cada segmento con Kokoro TTS (HTTP) según SRT -> chunks WAV, opcionalmente alinear y pad/trim para coincidir con duraciones.
- Concat/normalizar chunks y producir WAV final.
- Reemplazar la pista de audio del vídeo original con el WAV generado, o mezclar (mix) según flag.
- Quemar SRT en el vídeo (subtítulos quemados) y escribir artefactos en
output/<basename>/. - Limpieza: borrar workdir y, por defecto, también
/tmp/full_pipeline_*residuales salvo que se pase--keep-temp.
- Adaptadores y shims
- Diseño: la lógica del orquestador no hace llamadas directas a subprocessos; en su lugar inyecta adaptadores (dependency injection). Esto simplifica testing y permite sustituir implementaciones.
- Shims y scripts en la raíz (
run_full_pipeline.py,srt_to_kokoro.py,dub_and_burn.py,translate_srt_*) permanecen para compatibilidad con ejemplos y para facilitar pruebas manuales.
- Logging, artefactos y limpieza
- Logging centralizado a través de
configure_logging(verbose):- Crea carpetas
logs/infra,logs/usecases,logs/cli. - Añade RotatingFileHandler por tipo (rotación configurable) y handler de consola (INFO por defecto, DEBUG con
--verbose).
- Crea carpetas
- Salidas finales: si la ejecución no es
--dry-run, el orquestador mueve el vídeo final y artefactos relacionados aoutput/<basename>/. - Limpieza automática: por defecto se elimina el
workdiry se buscan y borran residuales/tmp/full_pipeline_*. Pasa--keep-temppara evitar borrado (útil para debugging).
- Flags y parámetros importantes
--video(required): ruta al vídeo fuente.--srt(opcional): usar SRT ya traducido (salta transcripción/traducción si procede).--kokoro-endpoint,--kokoro-key: URL y token para el servicio TTS.--voice,--kokoro-model: parámetros para la síntesis.--translate-method(local|gemini|argos|none): seleccionar estrategia de traducción.--gemini-key: clave para Gemini si se eligegemini.--dry-run: simula los pasos sin ejecutar (útil en CI o la primera ejecución).--keep-chunks,--keep-temp: conservar artefactos intermedios para debugging.--mix,--mix-background-volume: mezclar en lugar de reemplazar la pista de audio.--verbose: habilita logging DEBUG.
- Tests y verificación
- Proyecto contiene tests ligeros que verifican delegaciones y la API de ciertos adaptadores. Ejecutar:
python3 -m tests.run_tests
- Se recomienda ejecutar
--dry-runprimero y revisarlogs/antes de una ejecución real con red y servicios externos.
- Errores comunes y debugging rápido
- ModuleNotFoundError al ejecutar el script directamente: ejecutar con
-mdesde la raíz o usarPYTHONPATH=.. Mejor:python -m whisper_project.run_full_pipeline .... - Problemas con
ffmpeg: comprobarffmpegyffprobeen PATH y su versión. - Errores TTS/HTTP: revisar
--kokoro-endpointy--kokoro-key; inspeccionar logs enlogs/infrapara requests/response y payloads. - Si la traducción remota falla, el pipeline soporta fallback a
localsi está configurado o si el adaptador lo implementa.
- Recomendaciones de mejora
- Añadir tests que verifiquen la escritura de ficheros de log y la limpieza de temporales.
- Añadir un flag
--logs-dirpara poder personalizar la ubicación de logs en entornos CI. - Publicar el paquete en editable mode (
pip install -e .) para evitar dependencias enPYTHONPATHal ejecutar desde entornos automatizados.
Archivo generado automáticamente por la documentación del repositorio. Si quieres, lo adapto a formato docs/ + mkdocs o lo extiendo con diagramas mermaid y ejemplos de payloads para Kokoro.
Gestión y uso de los modelos (Whisper, Marian, Kokoro, Gemini)
Esta sección explica cómo gestionar y trabajar con los modelos utilizados en los distintos pasos del pipeline.
- Whisper / faster-whisper / openai-whisper
- Modelos comunes:
tiny,base,small,medium,large. - Recomendación: usar
baseosmallpara calidad razonable en CPU;medium/largerequieren GPU y más memoria. - faster-whisper: permite cargar modelos quantizados (int8, q4/q8) para reducir memoria. Ejemplo de carga:
- Modelos comunes:
from faster_whisper import WhisperModel
## Nota sobre unificación
Este archivo existía como una versión previa de la documentación. El contenido principal ha sido unificado en `DOCS/architecture.md` (archivo canónico). Para evitar ambigüedad, por favor usa `DOCS/architecture.md` como única referencia; ese archivo contiene la versión corregida del diagrama Mermaid y la referencia al recurso `DOCS/assets/pipeline_diagram.png`.
Si quieres que elimine este archivo por completo en una próxima acción, indícamelo y lo borro.
- Cache y ubicación: los modelos se descargan en el cache de transformers / faster-whisper (por defecto en `~/.cache/huggingface` o `~/.cache/faster-whisper`). Puedes cambiarlo con la variable `TRANSFORMERS_CACHE` o similar.